Yarn
Yarn
Yarn 概述
Yarn 资源调度器
Yarn 是一个资源调度平台,为运算程序提供服务器运算资源,类似于分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
Yarn 基础架构
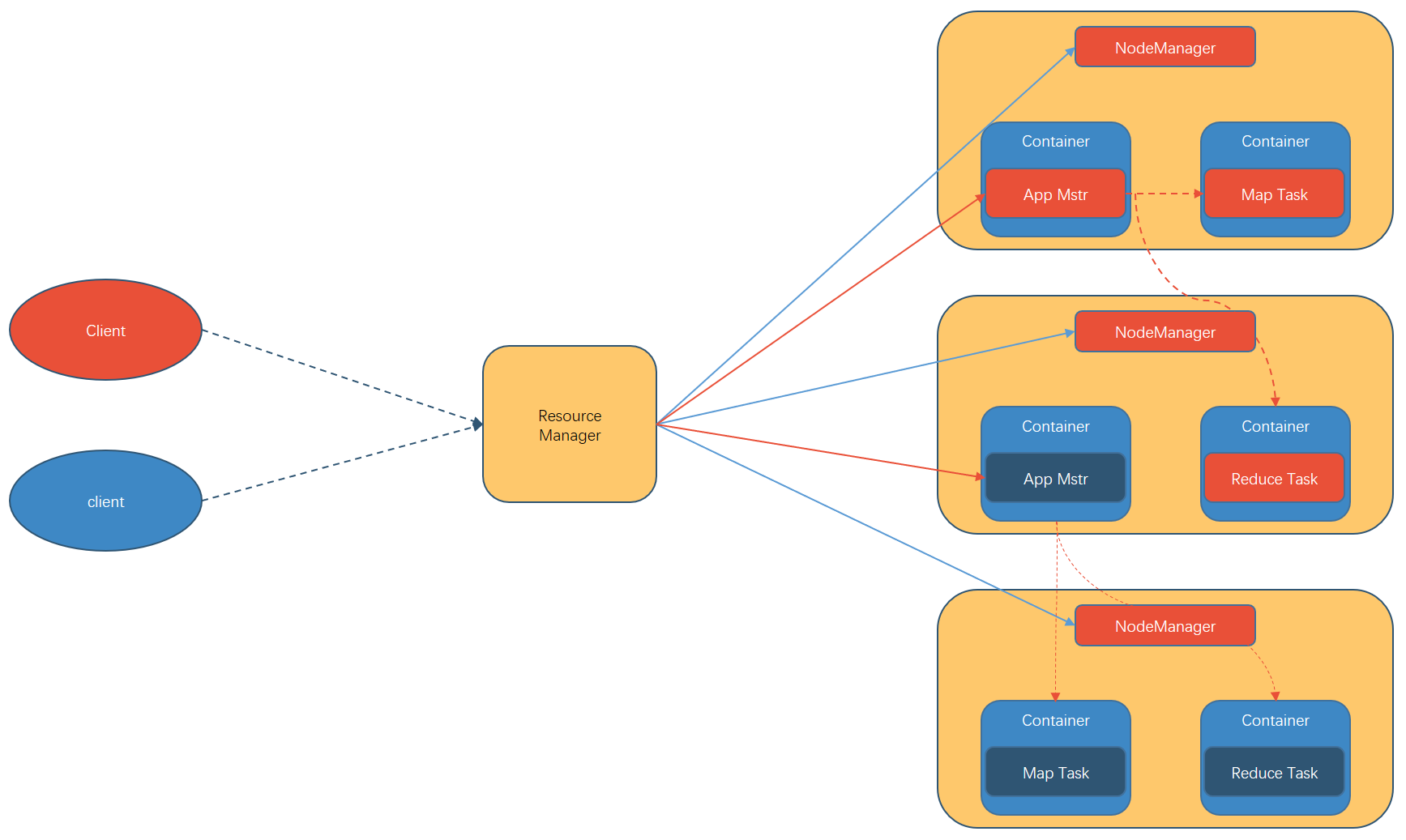
主要由:
ResourceManager:
- 处理客户端请求
- 监控 NodeManager
- 启动或监控 ApplicationMaster
- 资源的分配与调度
NodeManager:
- 管理单个节点上的资源
- 处理来自 ResourceManager 的命令
- 处理来自 ApplicationMaster 的命令
ApplicationMaster:
- 为应用程序申请资源并分配给内部的任务
- 任务的监控与容错
Container :
container 是 Yarn 中的资源抽象,它封装了某个节点上的多个维度资源,如 内存,cpu,磁盘,网络等
等组件构成
Yarn 工作机制
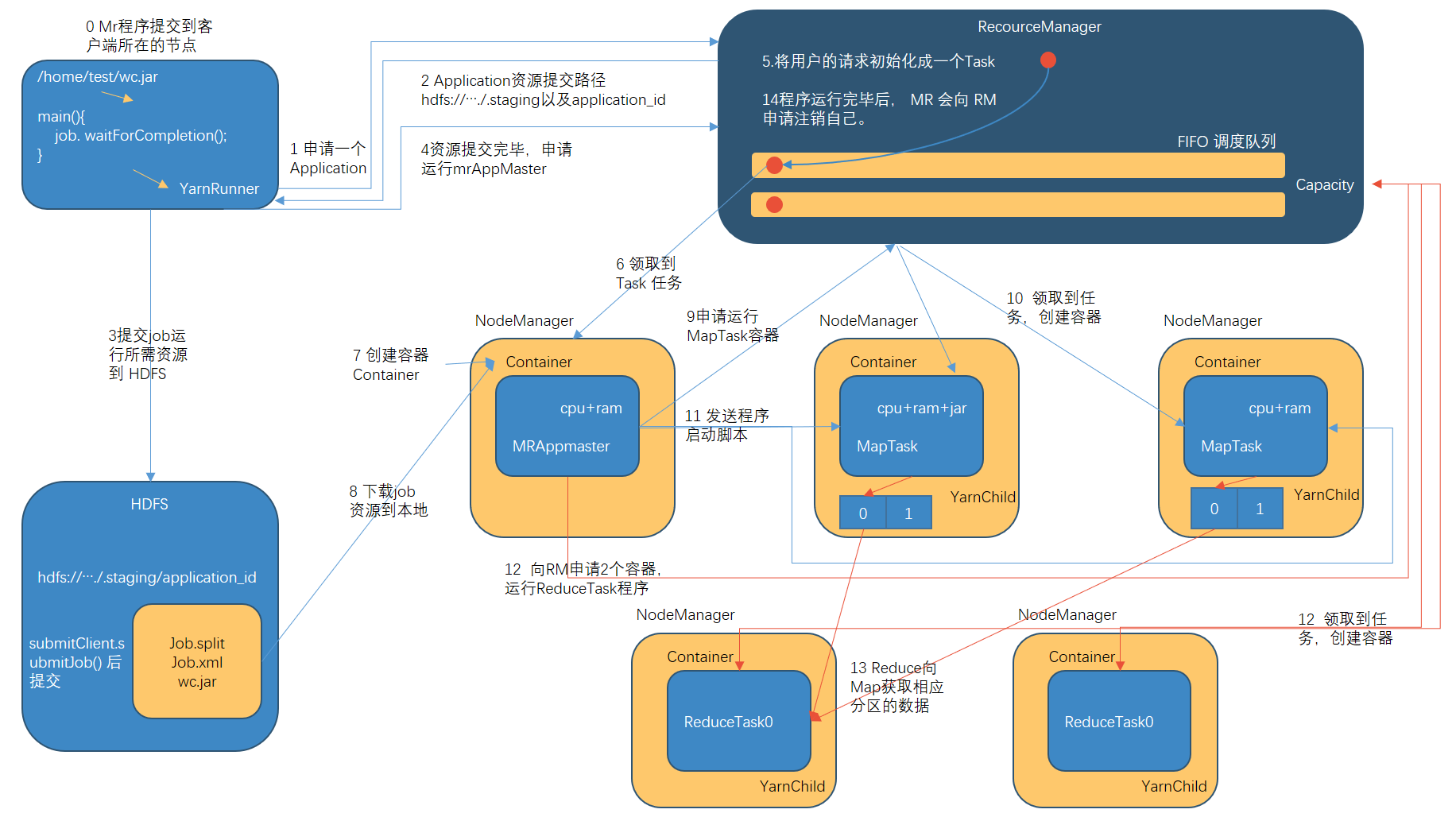
- MR 程序提交到客户端所在的节点。
- YarnRunner 向 ResourceManager 申请一个 Application。
- RM 将该应用程序的资源路径返回给 YarnRunner。
- 该程序将运行所需资源提交到 HDFS 上。
- 程序资源提交完毕后,申请运行 mrAppMaster。
- RM 将用户的请求初始化成一个 Task。
- 其中一个 NodeManager 领取到 Task 任务。
- 该 NodeManager 创建容器 Container, 并产生 MRAppmaster。
- Container 从 HDFS 上拷贝资源到本地。
- MRAppmaster 向 RM 申请运行 MapTask 资源
- RM 将运行 MapTask 任务分配给另外两个 NodeManager, 另两个 NodeManager 分
别领取任务并创建容器。 - MR 向两个接收到任务的 NodeManager 发送程序启动脚本, 这两个 NodeManager
分别启动 MapTask, MapTask 对数据分区排序。 - MrAppMaster 等待所有 MapTask 运行完毕后,向 RM 申请容器, 运行 ReduceTask。
- ReduceTask 向 MapTask 获取相应分区的数据。
- 程序运行完毕后, MR 会向 RM 申请注销自己。
作业提交全过程
HDFS、 YARN、 MapReduce 三者关系
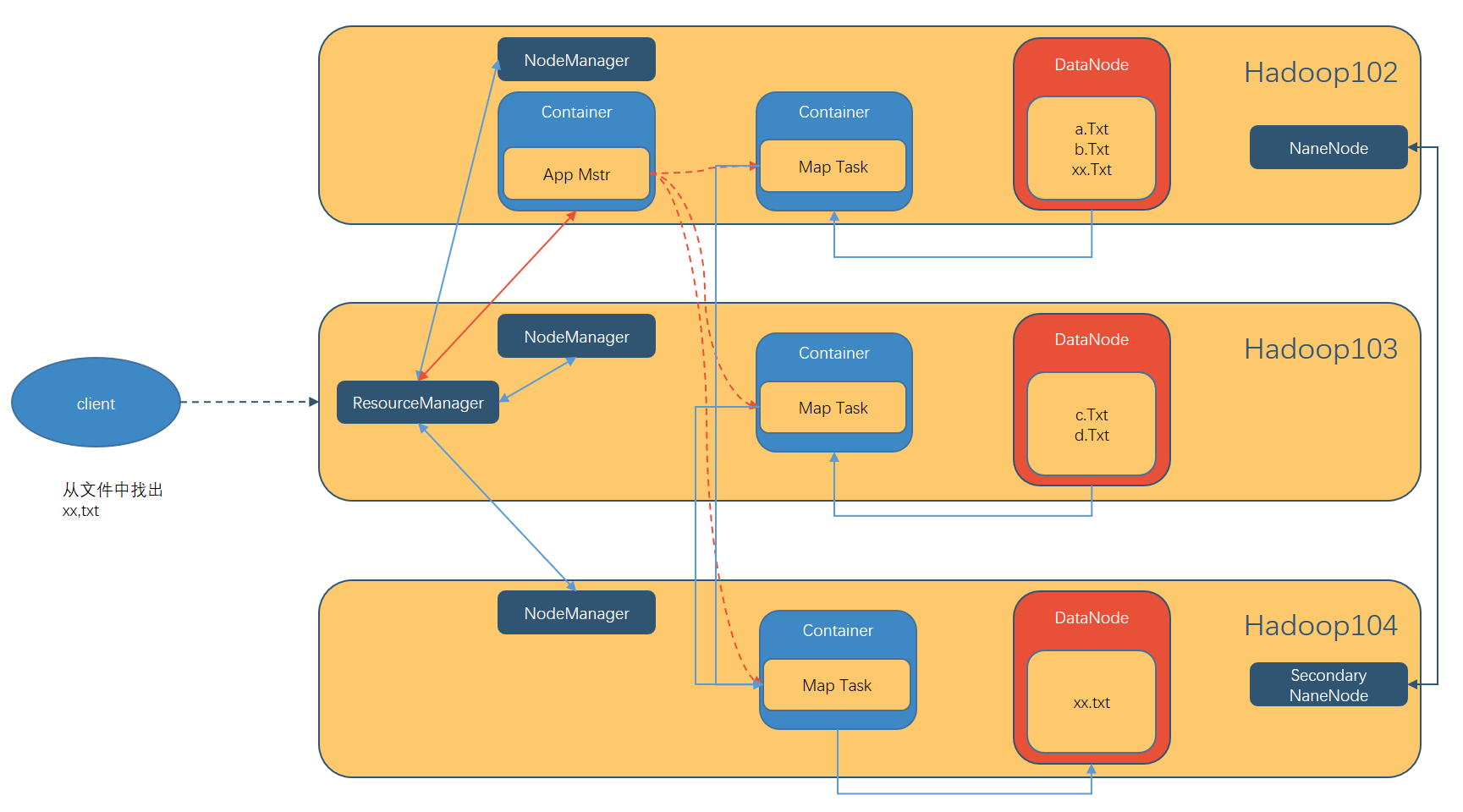
作业提交全过程
作业提交
- Client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业。
- Client 向 RM 申请一个作业 id。
- RM 给 Client 返回该 job 资源的提交路径和作业 id。
- Client 提交 jar 包、切片信息和配置文件到指定的资源提交路径。
- Client 提交完资源后,向 RM 申请运行 MrAppMaster。
作业初始化
- 当 RM 收到 Client 的请求后,将该 job 添加到容量调度器中。
- 某一个空闲的 NM 领取到该 Job。
- 该 NM 创建 Container, 并产生 MRAppmaster。
- 下载 Client 提交的资源到本地。
任务分配
- MrAppMaster 向 RM 申请运行多个 MapTask 任务资源。
- RM 将运行 MapTask 任务分配给另外两个 NodeManager, 另两个 NodeManager分别领取任务并创建容器。
任务运行
- MR 向两个接收到任务的 NodeManager 发送程序启动脚本, 这两个NodeManager 分别启动 MapTask, MapTask 对数据分区排序。
- MrAppMaster等待所有MapTask运行完毕后,向RM申请容器, 运行ReduceTask。
- ReduceTask 向 MapTask 获取相应分区的数据。
- 程序运行完毕后, MR 会向 RM 申请注销自己。
进度和状态更新
YARN 中的任务将其进度和状态(包括 counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval 设置)向应用管理器请求进度更新, 展示给用户。
作业完成
除了向应用管理器请求作业进度外, 客户端每 5 秒都会通过调用 waitForCompletion()来检查作业是否完成。 时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业完成之后, 应用管理器和 Container 会清理工作状态。 作业的信息会被作业历史服务器存储以备之后用户核查。
Yarn 调度器和调度算法
Hadoop 作业调度器主要有三种: FIFO、 容量(Capacity Scheduler) 和公平(Fair Scheduler) 。 Apache Hadoop3.1.3 默认的资源调度器是 Capacity Scheduler。
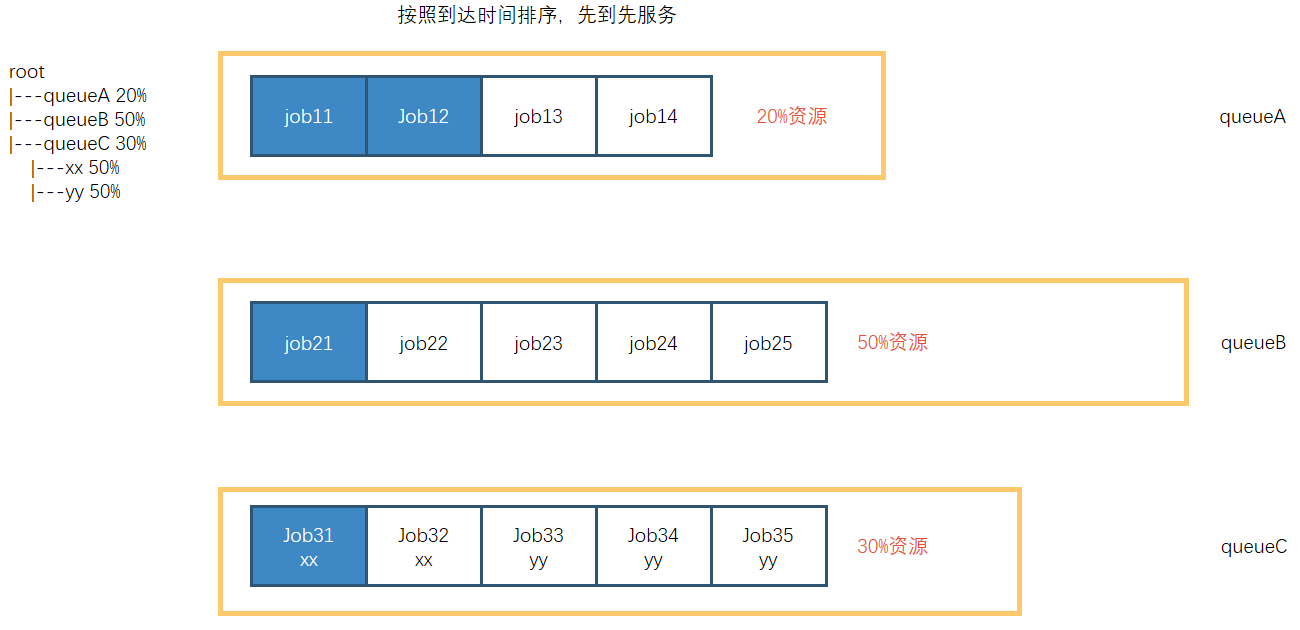
先进先出调度器(FIFO)
FIFO 调度器(First In First Out) :单队列,根据提交作业的先后顺序,先来先服务。
优点:简单易懂;
缺点:不支持多队列,生产环境很少使用;
容量调度器(Capacity Scheduler)
Capacity Scheduler 是 Yahoo 开发的多用户调度器。
特点:
多队列: 每个队列可配置一定的资源量,每个队列采用FIFO调度策略。
容量保证:管理员可为每个队列设置资源最低保证和资源使用上限
灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
多租户:
支持多用户共享集群和多应用程序同时运行。
为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
容量调度器资源分配算法
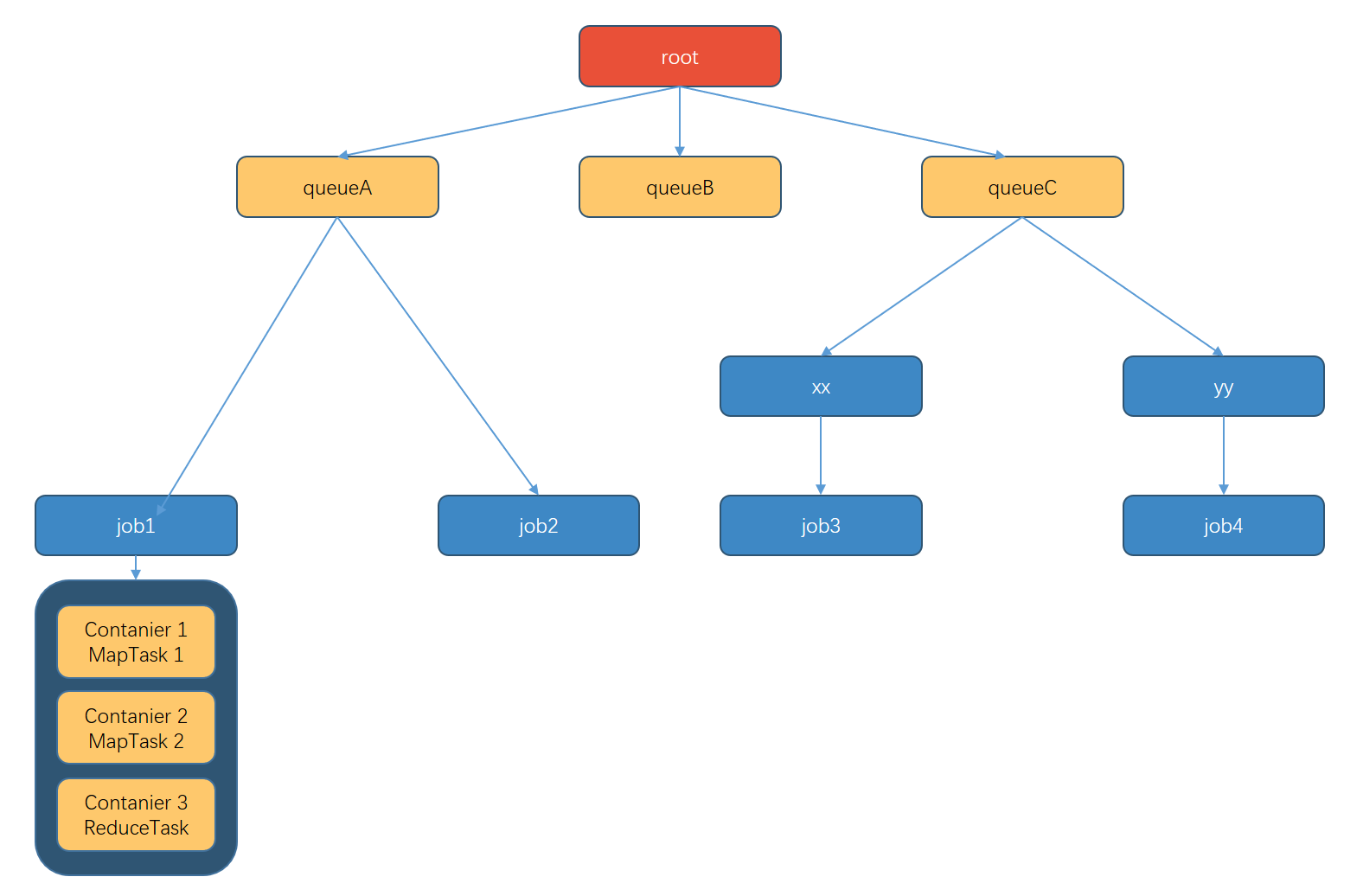
队列资源分配
从root开始,使用深度优先算法, 优先选择资源占用率最低的队列分配资源。
作业资源分配
默认按照提交
作业的优先级和提交时间顺序分配资源。容器资源分配
按照容器的优先级分配资源;
如果优先级相同,按照数据本地性原则:( 1)任务和数据在同一节点
( 2)任务和数据在同一机架
( 3)任务和数据不在同一节点也不在同一机架
公平调度器(Fair Scheduler)
Fair Schedulere 是 Facebook 开发的多用户调度器。
公平调度器特点
与容量调度器相同点
多队列:支持多队列多作业
容量保证:管理员可为每个队列设置资源最低保证和资源使用上线
灵活性: 如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
与容量调度器不同点
核心调度策略不同 :
容量调度器:优先选择资源利用率低的队列
公平调度器:优先选择对资源的缺额比例大的
每个队列可以单独设置资源分配方式:
容量调度器: FIFO、 DRF
公平调度器: FIFO、 FAIR、 DRF
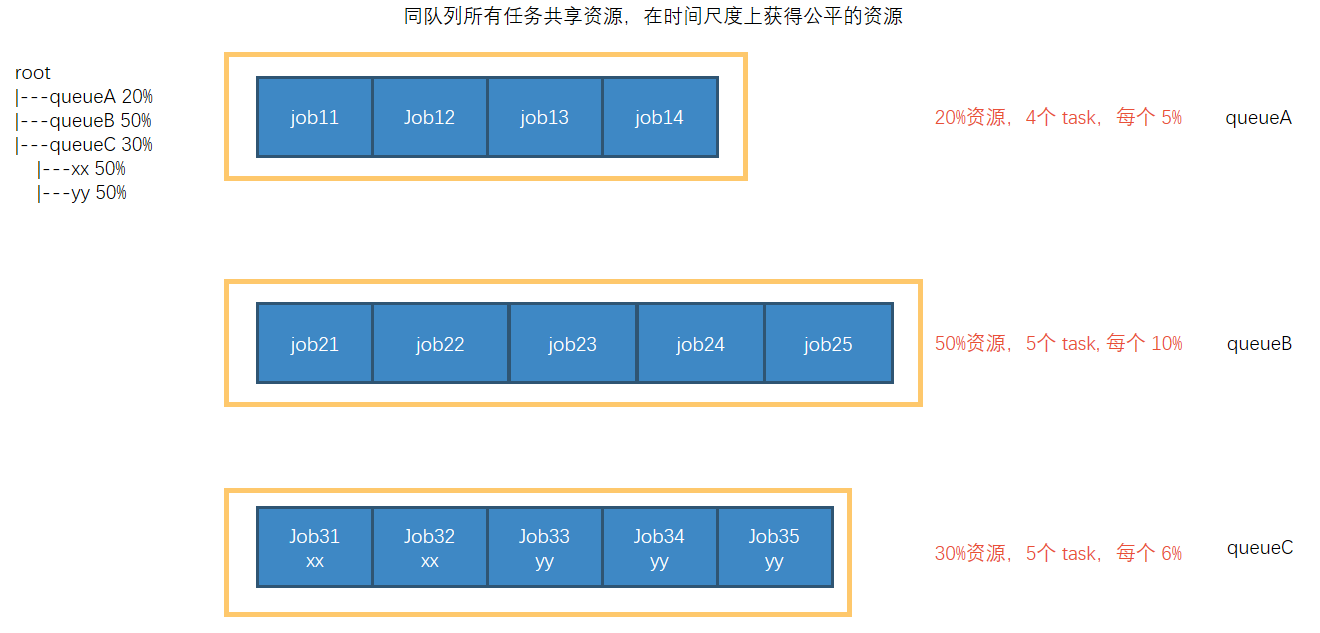
公平调度器——缺额
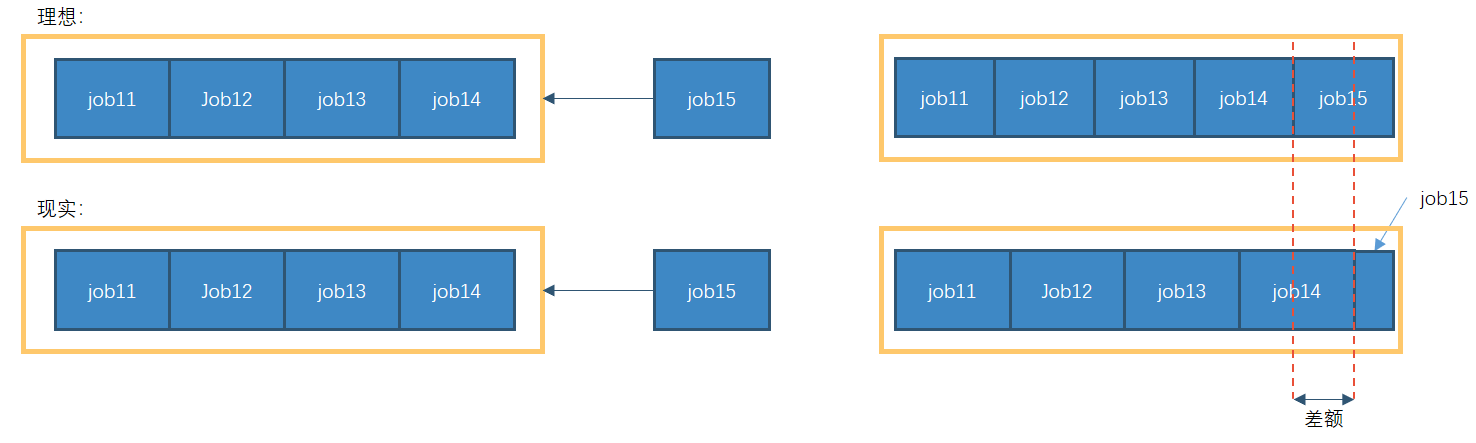
公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫“缺额”
调度器会优先为缺额大的作业分配资源
队列资源分配方式
FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话, 此时公平调度器相当于上面讲过的容量调度器。
Fair策略
Fair 策略(默认) 是一种基于最大最小公平算法实现的资源多路复用方式, 默认情况下, 每个队列内部采用该方式分配资源。 这意味着, 如果一个队列中有两个应用程序同时运行, 则每个应用程序可得到1/2的资源;如果三个应用程序同时运行, 则每个应用程序可得到1/3的资源。
公平调度器具体资源分配流程和容量调度器一致;
- 选择队列
- 选择作业
- 选择容器
以上三步, 每一步都是按照公平策略分配资源
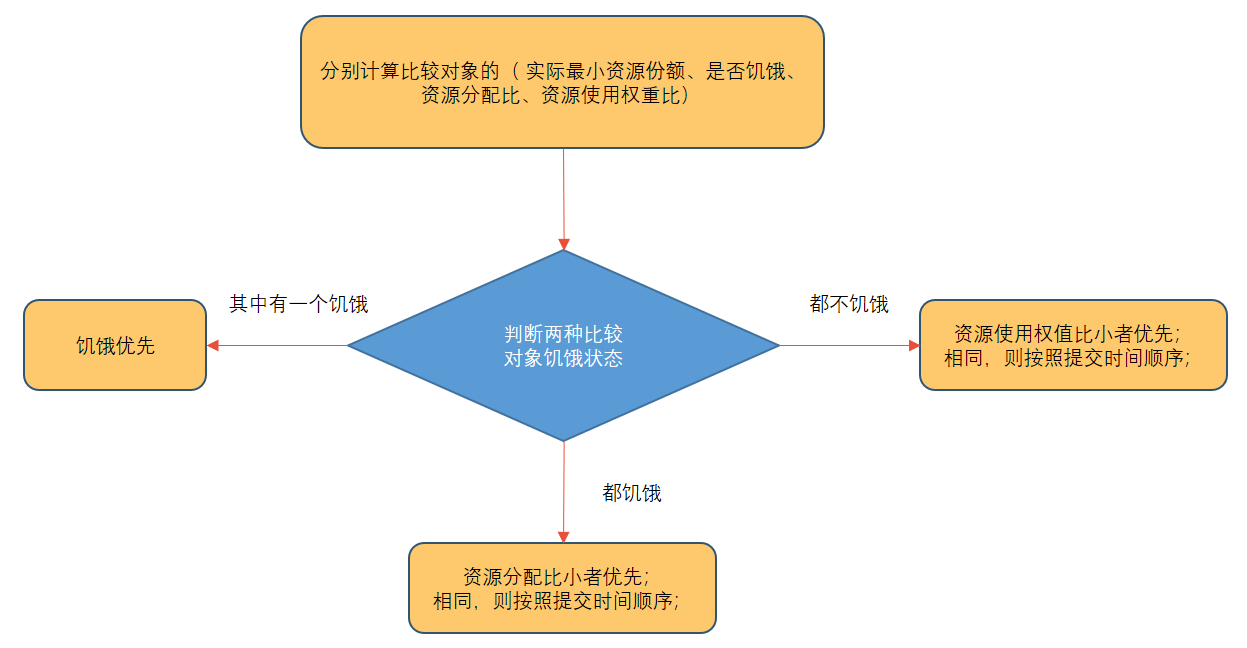
实际最小资源份额: mindshare = Min(资源需求量(4), 配置的最小资源(2))
是否饥饿: isNeedy = 资源使用量(1) < mindshare(实际最小资源份额(2))
资源分配比: minShareRatio = 资源使用量(1) / Max(mindshare(2), 1)
资源使用权重比: useToWeightRatio = 资源使用量 / 权重
DRF策略
DRF(Dominant Resource Fairness) , 我们之前说的资源, 都是单一标准, 例如只考虑内存(也是Yarn默认的情况) 。 但是很多时候我们资源有很多种, 例如内存, CPU, 网络带宽等, 这样我们很难衡量两个应用应该分配的资源比例。那么在YARN中, 我们用DRF来决定如何调度:
假设集群一共有100 CPU和10T 内存, 而应用A需要(2 CPU, 300GB) , 应用B需要(6 CPU, 100GB) 。则两个应用分别需要A(2%CPU, 3%内存) 和B(6%CPU, 1%内存) 的资源, 这就意味着A是内存主导的, B是CPU主导的, 针对这种情况, 我们可以选择DRF策略对不同应用进行不同资源(CPU和内存) 的一个不同比例的限制。
例子:(公平调度器资源分配算法 )
1)队列资源分配
集群总资源100,有三个队列,对资源的需求分别是:
queueA -> 20, queueB ->50, queueC -> 30
第一次算: 100 / 3 = 33.33
queueA:分33.33 → 多13.33
queueB:分33.33 → 少16.67
queueC: 分33.33 → 多3.33
第二次算: ( 13.33 + 3.33) / 1 = 16.66
queueA:分20
queueB:分33.33 + 16.66 = 50
queueC: 分30
2)作业资源分配
a) 不加权( 关注点是Job的个数) :
需求: 有一条队列总资源12个, 有4个job, 对资源的需求分别是:
job1->1, job2->2 , job3->6, job4->5
第一次算: 12 / 4 = 3
job1: 分3 –> 多2个
job2: 分3 –> 多1个
job3: 分3 –> 差3个
job4: 分3 –> 差2个
第二次算: 3 / 2 = 1.5
job1: 分1
job2: 分2
job3: 分3 –> 差3个 –> 分1.5 –> 最终: 4.5
job4: 分3 –> 差2个 –> 分1.5 –> 最终: 4.5
第n次算: 一直算到没有空闲资源
b)加权(关注点是Job的权重) :
需求: 有一条队列总资源16, 有4个job
对资源的需求分别是:
job1->4 job2->2 job3->10 job4->4
每个job的权重为:
job1->5 job2->8 job3->1 job4->2
第一次算: 16 / (5+8+1+2) = 1
job1: 分5(权重) –> 多1
job2: 分8 –> 多6
job3: 分1 –> 少9
job4: 分2 –> 少2
第二次算: 7 / (1+2) = 7/3
job1: 分4
job2: 分2
job3: 分1 –> 分7/3(2.33) –>少6.67
job4: 分2 –> 分14/3(4.66) –>多2.66
第三次算:2.66/1=2.66
job1: 分4
job2: 分2
job3: 分1 –> 分2.66/1 –> 分2.66
job4: 分4
调度器选择
在生产环境下怎么选择?
大厂:如果对并发度要求比较高,选择公平,要求服务器性能必须OK;
中小公司,集群服务器资源不太充裕选择容量。
在生产环境怎么创建队列?
调度器默认就1个default队列,不能满足生产要求。
按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)
按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2
创建多队列的好处?
因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
实现任务的降级使用,特殊时期保证重要的任务队列资源充足。
业务部门1(重要)=》业务部门2(比较重要)=》下单(一般)=》购物车(一般)=》登录注册(次要)
Yarn 生产环境核心参数
ResourceManager相关
配置调度器, 默认容量 :yarn.resourcemanager.scheduler.class
ResourceManager处理调度器请求的线程数量, 默认50:
arn.resourcemanager.scheduler.client.thread-count
NodeManager相关
是否让yarn自己检测硬件进行配置, 默认false:
yarn.nodemanager.resource.detect-hardware-capabilities
是否将虚拟核数当作CPU核数, 默认false:
yarn.nodemanager.resource.count-logical-processors-as-cores
虚拟核数和物理核数乘数, 例如: 4核8线程, 该
参数就应设为2, 默认1.0 :yarn.nodemanager.resource.pcores-vcores-multiplier
NodeManager使用内存, 默认8G:
yarn.nodemanager.resource.memory-mb
NodeManager 为系统保留多少内存以上二个参数配置一个即可:
yarn.nodemanager.resource.system-reserved-memory-mb
NodeManager使用CPU核数, 默认8个 :
yarn.nodemanager.resource.cpu-vcores
是否开启物理内存检查限制container, 默认打开 :
yarn.nodemanager.pmem-check-enabled
是否开启虚拟内存检查限制container, 默认打开:
yarn.nodemanager.vmem-check-enabled
虚拟内存物理内存比例, 默认2.1:
yarn.nodemanager.vmem-pmem-ratio
Container相关:
容器最最小内存, 默认1G:
yarn.scheduler.minimum-allocation-mb
容器最最大内存, 默认8G:
yarn.scheduler.maximum-allocation-mb
容器最小CPU核数, 默认1个 :
yarn.scheduler.minimum-allocation-vcores
容器最大CPU核数, 默认4个:
yarn.scheduler.maximum-allocation-vcores
Hadoop 相关补充
基准测试
搭建完Hadoop集群后需要对HDFS读写性能和MR计算能力测试。测试jar包在hadoop的share文件夹下。
集群总吞吐量 = 带宽*集群节点个数/副本数
例如:100m/s * 10台/ 3= 333m/s
注意:如果测试数据在本地,那副本数-1。因为这个副本不占集群吞吐量。如果数据在集群外,向该集群上传,需要占用带宽。本公式就不用减1。
Hadoop宕机
- 如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
- 如果写入文件过快造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。例如,可以调整Flume每批次拉取数据量的大小参数batchsize。
Hadoop解决数据倾斜方法
提前在map进行combine,减少传输的数据量
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key大量分布在不同的mapper的时候,这种方法就不是很有效了。
导致数据倾斜的key 大量分布在不同的mapper
(1)局部聚合加全局聚合。
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差。
(2)增加Reducer,提升并行度
JobConf.setNumReduceTasks(int)(3)实现自定义分区
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer